

I often came across situations where the old school search query on the SQL database was just not good enough to handle the fast amounts of data maintained within normalized relational database structures.
I did a little research and found RediSearch developed by Redis. RediSearch implements a powerful full-text and Secondary Index engine on top of Redis, it is different from other Redis search engines, using its own highly optimized data structures and algorithms it gives excellent performance and advanced features.
Full-text search
In this post, I would like to explore the full-text search feature in more detail because it solves a set of problems I come across most often regarding complex searching and performance. There are other great features like complex boolean queries between sub-queries, Field weights, Geo filtering and more.
The full-text search uses term indexing to perform more advanced searches on databases. The term indexing eliminates the need to scan rows or having to know the column a term is stored in, resulting in quick and advanced search capabilities as well as load reduction on your primary database.
RediSearch gives you a rich query language that allows you to search: selections of specific fields, exact phrase, negation, prefix, wildcard, union, optional, and combinations of terms. See the query syntax documentation here for detailed examples.
The Solution
Let’s look at how we can implement RediSearch to improve performance when performing complex search queries. In our scenario, we are going to save companies with properties Id, Name, and Description and then do a full-text search on those properties. The technologies involved are Blazor, dotnet Core, Redis Server, RediSearch module, Topsshelf, RabbitMQ, and SQL.
Using a NoSQL in-memory data structure store Like Redis in conjunction with a relational database, brings new challenges such as achieving strong or eventual consistency across the SQL and NoSQL database, We can achieve both with a linearizable approach using a service-oriented architecture or with the aggregate pattern. The Architecture titled Architecture below is an eventual consistency implementation.
Eventual consistency gives us a weak guarantee that both data sources will be updated with the same data in an unknown time frame whereas strong consistency will guarantee both updates immediately.
Advantages of eventual consistency are when performing our subsequent operation, updating our NoSQL database, using a decoupled event-driven approach the user will not be affected by the save operation of the company or the outcome of the operation thus giving us lower latency. Unfortunately to our disadvantage we are moving away from the aggregate pattern and losing its advantage of a single transaction. If our subsequent operation fails it will be more effort to revert previously applied operations if required (in our scenario we do not want to revert any changes). If eventual consistency takes to long we run the risk of returning stale data on the search.
If we use strong consistency we can take advantage of the single transaction the aggregate pattern has to offer, guarantee up-to-date synchronized data, and roll back any changes made by the save operation however we risk affecting the user with higher latency. To achieve this the SaveCompanyAggregate calls the SaveCompanyRediSAggregate directly within the same scope.
If we use strong consistency we can take advantage of the single transaction the aggregate pattern has to offer, guarantee up-to-date synchronized data, and roll back any changes made by the save operation however we risk affecting the user with higher latency. To achieve this the SaveCompanyAggregate calls the SaveCompanyRediSAggregate directly within the same scope (directly from code and not via the service bus).
The Project
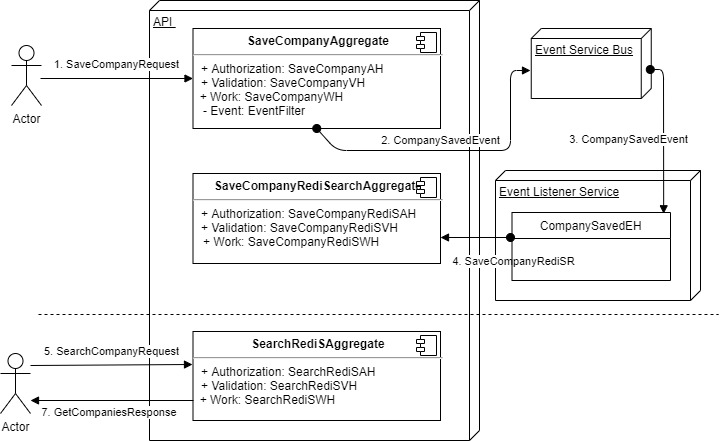
From the Blazor UI a user enters a name and a description followed by clicking on the save button, this initiates the SaveCompanyRequest. The dotnet Core API receives the request and passes it to the execution pipeline which resolves the SaveCompanyAggregate. The aggregate consists of an AuthorizationHandler, ValidationHandler, and a WorkerHandler. After authorization and validation pass the SaveCompanyWorkerHandler saves the Company to the SQL Database, on success, the handler adds a CompanySavedEvent that is sent to the service bus. The CompanySavedEventHandler picks up the event and initiates a SaveCompanyRediSRequest to the API. Same as the previous aggregate the authorization and validation for the subsequent aggregate will execute, on success, the worker handler updates the RediSearch data store with the new values. From the Blazor UI, the user can now search for the company by initiating the SearchCompanyRequest.
We are going to discuss a selected set of classes in this post, for access to the full project, please access the Github project here. In the sample project, I set all the Authorization Handlers (AH) to allow anonymous calls to demonstrate RediSearch. In a real-world scenario, the handlers would use the IsLoggedin() method, also, the SaveCompanyRediSAH will check for a specific system role to ensure, an authenticated system principle can only initiate it.
The Code
CompanySave.razor
The Save method uses the ApiPostController class to create a new SaveCompanyRequest on lines 40 and 41. On success, a message is added to for display, when the post to the API is completed all the messages returned from the API are added to display. The request object is initiated on line 55 in the Post method. The Post method initialized the request.
SaveCompanyWorkerHandler.cs
The GetEntity method on line 13 will create a new company if the Id received is 0, if the Id received is greater then 0 it will attempt to resolve the company from the DB. If an entity is not found an E4 (not found) message will be raised in the ValidateEntity method on lines 21 and 22. The Execute method will map the request to the entity and persist the result to the relational database, after which it will set the result and raise the CompanySavedEvent on line 37.
CompanySavedEventHandler.cs
This handler resides with the event manager (event service bus). This layer does not have access to the domain or database and is simply responsible for delegating and orchestration communication to APIs: also known as the Saga Manager in the Orchestration-Based Saga microservice pattern. It Uses the same ApiPostController as seen in the Blazor UI to post requests to the API.
SaveCompanyRediSWorkerHandler.cs
This handler has a single Execute method and is not associated with a relational database entity. The method establishes a connection to the Redis-Server, configures the index we are adding or updating to, followed by calling the Redis AddDocument with a replacement policy set to full and finally, sets the response.
CompanySearch.razor
When the user initiates the Search method a SearchRediSRequest is created and posted to the API, on success, the result with a success message is set for display.
SearchRediSWorkerHandler.cs
The single Execute method establishes a connection to the Redis-Server, sets up the index and performs the query, finally, the result is created and returned. The index we want to search is passed along with the SearchRediSRequest and the response is of type dynamic making this handler generic to all indexes and searches. The result contains a list of RediSResult DTOs each containing the Score and Data representing a single Company.
Docker for RediSearch
A docker image for RediSearch can be found here. Throughout the development project of this I hosted this image using Azure Containers, please find the ARM template here
Last words
With our code in place, we can now use the search syntax described in the RediSearch documentation to perform complex text searches on our data. The microservice architecture will increase performance, allow for scalability, and assist in achieving eventual consistency. The micromodule framework assisted us in developing small aggregates, increasing reusability, and easy testing. Along with the microservice architecture, we can orchestrate our solutions in different ways without affecting the implementation.
References
https://redis.com/blog/redis-on-windows-10/
https://redis.com/blog/mastering-redisearch-part/
https://en.wikipedia.org/wiki/Linearizability#/media/File:Linearlizable_Process.svg
{kind=link}
https://stackexchange.github.io/StackExchange.Redis/Basics
https://oss.redislabs.com/redisearch/Query_Syntax.html